Newvelles, a portmanteau between New and Nouvelles (french word for news), so in other words Latest News, is a simple website (available at this link) that allows you to navigate the latest news clustered by topics.
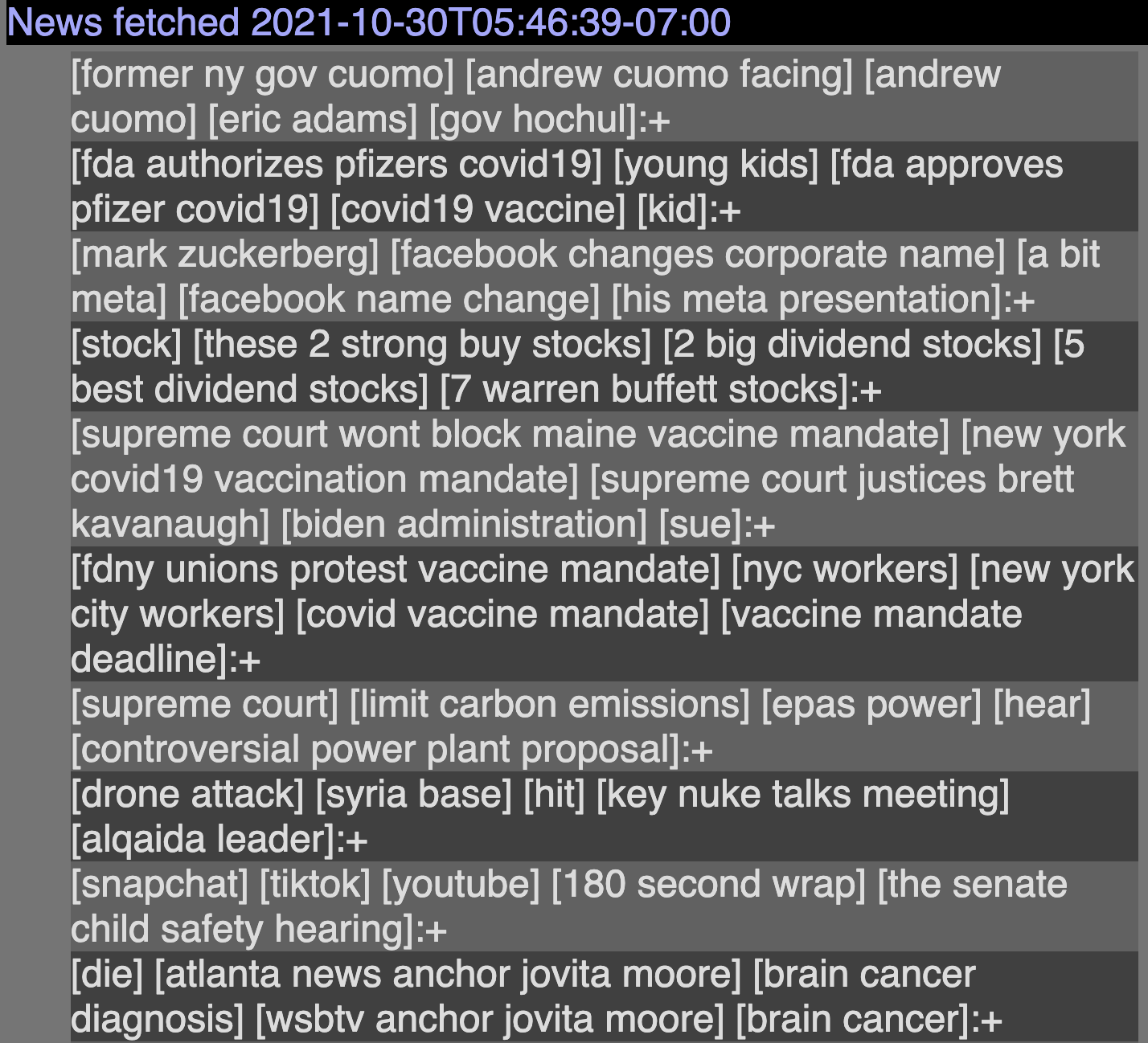
Example top 10 news fetched on Nov 30th at 5:46am PDT.
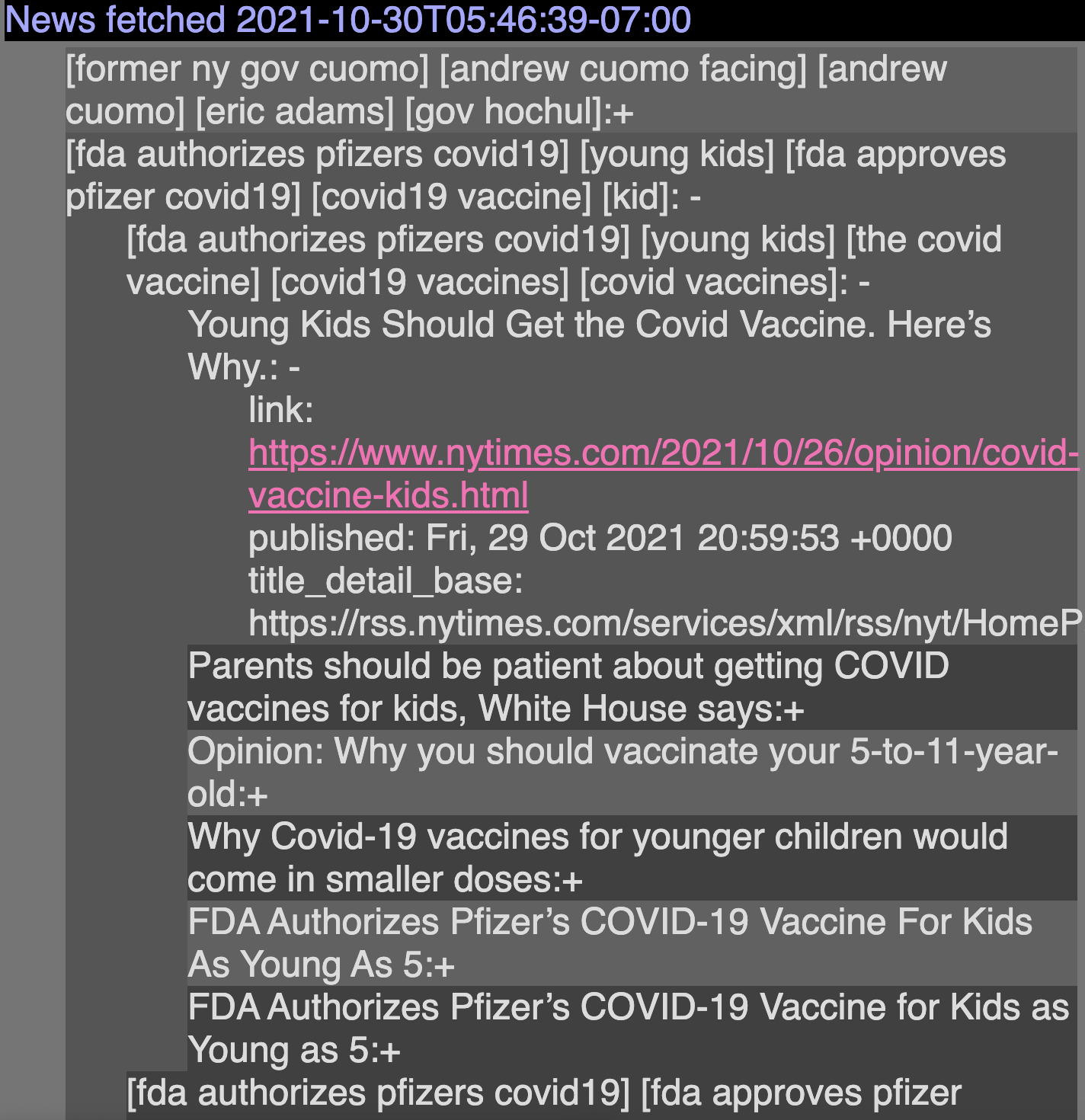
Example of expanded top-level cluster all the way to the last level with the metadata.
All news are grouped into two levels. First by their “semantic similarity” (they have content that covers similar topics) and then by their potential duplicates (they have the same content). All are ranked by frequency (size of the top-level cluster). For each cluster, a set of noun phrases is extracted and then displayed so the user can infer the content within each cluster of news.
Users can navigate the news by expanding the top-level (same topics) news and the second-level news (duplicates). The last level of the tree contains metadata of the particular news and a link to access the full article from the source.
How does Newvelles work?
At a very high level, the production version of Newvelles works in the following way:
- Every ~3 hours, it triggers a python script in AWS Lambda that fetches raw news data from a list of valid RSS feeds.
- For every RSS news site, the job pulls all the latest news (filtering anything older than 14 days), processes it, and dumps it to AWS S3.
- The processed news is consumed from S3 by a simple website hosted in AWS Lightsail, which then presents the content to end users.
You can definitely run it 100% locally (no need to have S3, AWS lambda, or AWS lightsail). You just need to follow the instructions in Newvelles (the backend that fetches and processes all news) and launch the Newvelles website (to navigate the data). You can also check each project’s Dockerfile for more details on how to run them locally.
The “news grouping algorithm” uses a combination of semantic similarity and text-matching similarity. The semantic similarity uses the Universal Sentence Encoder to encode news titles into sentence embeddings to find which other titles are close using simple similarity measures. The current implementation uses a pre-trained collection of embeddings available in TensorHub, particularly the lite version. The text matching similarity uses a very simple algorithm that transforms all encoded words from the sentence into a set. It then iteratively builds groups of similar sentences based on how many common words (non-stopwords and stemmed) are shared between these sets.
TODO
Several improvements can be done in future versions:
- Better UX to navigate the news. For example, using size to change which noun phrases are most common within a particular cluster or improving the topic similarity algorithm (expanding it beyond just using the Universal Sentence Encoder).
- Better matching algorithms to group duplicate news. The current matching algorithm is extremely simple.
- Allow users to pick their own set of RSS news links to personalize which news they are interested in following. This might need users to keep on their own cache unless a user registration process is created.
- News websites can be polarized, and it’s well understood which direction of the political spectrum they can lean. Adding this metadata to the RSS news list and then using it to label how different news clusters are distributed along the political spectrum (e.g., in terms of coverage) could be an interesting feature to explore.
You are more than welcome to take a stab and contribute to any of these topics. Pull requests are welcome!